In this post I’m going to discuss and demonstrate how to create a streaming pipeline component. I’ll show some of the benefits and also highlight the challenges I encountered using the BizTalk VirtualStream class.
I’m using BizTalk 2013 R2 for the purposes of this demonstration (update: or I was until my Azure dev VM died due to an evaluation edition of SQL Server expiring – I switched to just BizTalk 2013).
If you would like the short version of this post, the code can be viewed here and the git clone URL is: https://github.com/jamescorbould/Ajax.BizTalk.DocMan.git (hope you read on though ;-)).
The Place of the Pipeline Component
As we all know, a pipeline contains one or many pipeline components. Pipeline components can be custom written and also BizTalk includes various “out of the box” components for common tasks. In most cases, a pipeline is configured on a port to execute on receiving a message and on sending a message.
On the receive, the flow is: adapter –> pipeline –> map –> messagebox.
On the send, the flow is: messagebox –> map –> pipeline –> adapter.
What is a “Non-Streaming” Pipeline Component?
Typically, such a pipeline component implements one or more of the following practices:
- Whole messages are loaded into memory in one go instead of one small chunk at a time (to ensure a consistent memory footprint, irrespective of message size). If the message is large, this practice can consume a lot of memory leading to a poorly performing pipeline and also potential triggering a throttling condition for the host instance.
- Messages are loaded into an XML DOM (Document Object Model) in order to be manipulated, for example using XMLDocument or XDocument. This causes the message to be loaded entirely into memory into a DOM, creating a much larger memory footprint than the actual message size (some sources indicate 10 times larger than the file size). Similarly (to a lesser extent than loading into a DOM), loading a message into a string datatype will result in the entire message being written into memory.
- Messages are not returned to the pipeline shortly after being received; instead, messages are processed and then returned to the pipeline. So further pipeline processing is blocked until the pipeline component has completed processing.
Example 1: Non-Streaming Pipeline Component
Here is an example of a non-streaming pipeline component (the entire solution can be downloaded as indicated in the intro to this post: this code is located in project Ajax.BizTalk.DocMan.PipelineComponent.Base64Encode.NotStreamingBad).

Fig 1. Non Streaming Pipeline Component Example
As shown, the example encodes a stream into neutral base64 format for sending on the wire and inserts it into another message…
In summary, this example is less than optimal:
- It uses XDocument which loads the message entirely into memory in one go, into a DOM, which is memory intensive for large messages.
- Control is not returned to the pipeline straightaway; the pipeline component does some processing and then returns control to the pipeline which means pipeline processing is blocked until this pipeline component completes processing the message. This potentially slows pipeline processing down.
Example 2: Streaming Pipeline Component
BizTalk ships with some custom streaming classes in the Microsoft.BizTalk.Streaming namespace and there are a number of sources out there that detail how to use them (please see the “Further Resources” section at the end of this post for a list of some that I have found).
As mentioned in the title of this blog post, the one I have used in this example is the VirtualStream class. It’s “virtual” since it uses disk (a temporary file) as a backing store (instead of memory) for storing bytes exceeding the configurable threshold size: this reduces and ensures a consistent memory footprint. A couple of potential disadvantages that come to mind is the extra possible latency of disk IO (for large messages) and also the possible security risk of writing sensitive (unencrypted) messages to disk.
I also observed that the temporary files created by the VirtualStream class (written to the Temp folder in the host instance AppData directory e.g C:\Users\{HostInstanceSvcAccount}\AppData\Local\Temp) are not deleted until a host instance restart. This is also something to consider when using the class to ensure that sufficient disk space exists for the temporary files and also that a strategy exists to purge the files.
In this implementation, I have written a custom stream class (Base64EncoderStream) that wraps a VirtualStream (i.e. an implementation of the “decorator” pattern). I noticed that the BizTalk EPM (Endpoint Processing Manager) only calls the Read method on streams… So logic to base64 encode some bytes was inserted into the (overidden) Read method.
The Read method is called by the EPM repeatedly until all bytes have been read from the backing store (which in the case of this implementation, could be memory or a file on disk). The EPM provides a pointer to a byte array and it’s the job of the Read method to populate the byte array, obviously ensuring not to exceed the size of the buffer. In this way, the stream is read one small chunk (4096 bytes) at a time, orchestrated by the EPM, thereby reducing the processing memory footprint.
Here’s the code for the Read method:

Fig 2. Read Method in Base64EncoderStream Class (note: may need to zoom in to view!)
Inside the execute method of the pipeline component, the constructor on the VirtualStream subclass is called, passing in the original underlying data stream as follows:

Fig. 3 Execute Method in StreamingGood Pipeline Component
So, as shown in the screenshot above, by returning the stream back to the pipeline as quickly as possible, we ensure that the next pipeline component can be initialized and potentially start working on the message and so on with the next components in the chain (i.e. it is now a true “streaming” pipeline component).
Performance Metrics
I decided to compare the performance of both implementations, comparing the following metrics:
- Memory consumption
- Processing latency
I would say that 1 (memory consumption) is of greater importance to get right than 2 (latency). That is, the impact of not getting 1 correct is greater than not getting 2 correct. Both are important considerations though.
For the purposes of the tests, I created two separate host instances and configured two Send Ports containing a pipeline containing the streaming and non-streaming pipeline component respectively, with each Send Port running within it’s own host instance.
I then ran up perfmon to compare memory consumption, capturing the private bytes counter for each host instance. Not suprisingly, the pipeline containing the streaming pipeline component had a much smaller and consistent memory footprint as can be observed in the screenshots below, using a file approximately 44MB in size:
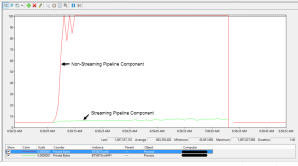
Fig. 4 Comparison of Memory Consumption #1

Fig 5. Comparison of Memory Consumption #2
Each spike of memory consumption associated with the streaming component I believe is due to loading each chunk of bytes into a string (as can be observed in Fig. 5).
One thing I noticed for both pipeline components is that the after processing had finished, memory consumption did not return to the pre-processing level until host instances where restarted, even though I had added object pointers to the pipeline component resource tracker (to ensure object disposable). However, memory consumption for the streaming pipeline remained at a consistent level no matter the number of files submitted for processing while the non streaming pipeline consumed more memory. This behaviour is mentioned in Yossi Dahan’s white paper in Appendix C [REF-1].
I decided to measure processing latency by noting the time that pipeline component execution commenced (using the CAT Teams tracing framework) and the final LastWriteTime property on the outputted file (using PowerShell). So this final time indicates when the file adapter has completed writing the file and BizTalk has completed processing.
Here are some approximate processing times using 2 sample files:
| File Size (MB) |
Streaming (mm:ss) |
Non-Streaming (mm:ss) |
| 5.5 |
1:01 |
0:44 |
| 44 |
27:02 |
5:29 |
I had a hunch that the higher processing latency of the streaming component was primarily due to the disk IO associated with using the VirtualStream class. Under the hood, when configured to use a file for storing bytes exceeding the byte count threshold, the VirtualStream class switches to wrap an instance of FileStream for the writing of overflow bytes. I figured that if I increased the size of the buffer used by the FileStream instance, this would mean less disk read and writes (at the expense of greater memory usage).
(As a side note, the default buffer and threshold sizes specified in the VirtualStream class are both 10240 bytes. Also, the maximum buffer and threshold size is 10485760 bytes (c. 10.5MB)).
Unfortunately and surprisingly, increasing the size of the buffer made no difference – processing latency was still the same. Maybe I will investigate this further in another blog post since I have already written a book in this post!!
Conclusion
I have demonstrated here that implementing a pipeline component in a streaming fashion has major benefits over a non-streaming approach. A streaming component consumes less memory and ensures a consistent memory footprint, regardless of message size.
Another finding is that the VirtualStream class adds significant processing latency (at least in this particular implementation) and unless this is not of concern, means that this class is only really suitable when working with small files.
Some Further Resources
Yossi Dahan, Developing a Streaming Pipeline Component for BizTalk Server, Published Feb 2010 [REF-1]
Available from: http://www.microsoft.com/en-us/download/details.aspx?id=20375
(I found this an extremely useful white paper (Word document format) which I must have reread many times now!).
Mark Brimble, Connected Pawns Blog
Optimising Pipeline Performance: Do not read the message into a string
Optimising Pipeline Performance: XMLWriter vs. XDocument
My colleague Mark wrote a series of blog posts comparing the performance of non-streaming pipeline components vs. streaming pipeline components.
Guidelines on MSDN for Optimizing Pipeline Performance
Developing Streaming Pipeline Components Series
Simplify Streaming Pipeline Components in BizTalk


















